Paradox of tolerance - Wikipedia
EN.M.WIKIPEDIA.ORG
👍3
$ cat >lol.txt
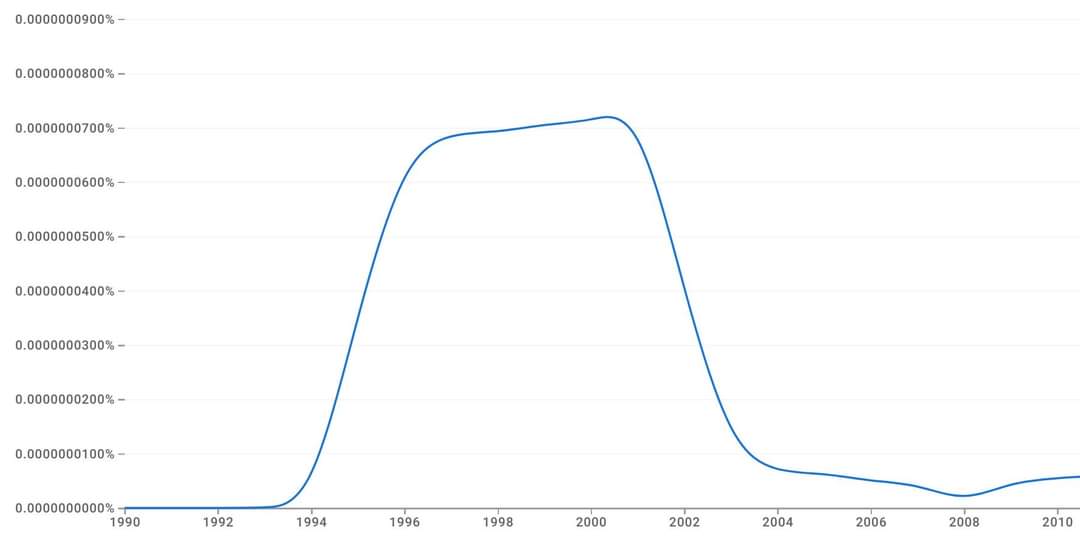
Y2K articles before year 2000:
"OMG, rogue Y2K is going to kill us all!"
Y2K articles after year 2000:
"Hahaha, remember how everyone was so scared of Y2K? ROFL!"
#humor #libertarian

На фото — разноцветные бабочки теснятся на голове каймана, чтобы получить доступ к крокодиловым слезам — важному источнику соли.
Этот снимок, сделанный Марком Кауэном (Marc Cowan) в Бразилии на берегах Амазонки, был удостоен специальной награды на фотоконкурсе издательства Лондонского королевского общества 2016 года (2016 Royal Society Publishing photography competition) в категории «Экология и наука об окружающей среде».

Вроде как для развития рекурсивного языка и сложного воображения существует короткий период, в который ребенок должен получить опыт этого языка, чтобы его развить. Сначала его не было много поколений, хотя вроде как всё необходимое было. Не было культуры. Вот тут гипотеза бутстрапа языка, начиная с двух мутантов, у которых этот период был дольше и его хватило, чтоб изобрести язык для общения друг с другом и дальше язык лавинообразно распространился.
https://www.ancientpages.com/2023/05/11/70000-years-ago-event-mystery-of-language-evolution/

#humor #anarchism

Better dig channels from the Azov sea to Caspian sea to Aral sea to Baikal, and form Azov / Caspian to Arctic Ocean and Baltic sea. Wide channels!
First, water transport is much cheaper and no need to maintain "roads". Second, this will transform tellurocratic russian "heartland" pushing it towards aggression against other countries to thallasocraties, that is, to what shaped European and Mediterranean civilizations.
https://bigthink.com/strange-maps/intercontinental-railway/
Люди обычно считают себя единственными животными, способными к сложным рассуждениям. Американские нейрологи показали, что это не так.
В поставленном ими эксперименте макаки-резусы использовали довольно сложные оптимизационные алгоритмы для получения максимальной награды, причём эксперимент показал, что разные обезьяны, как и разные люди, оптимизируют по разным параметрам.
Для начала двух обезьян научили, что при нажатии разных картинок на экране им дают разное количество смородинового сока, причём каждая картинка соответствует определённому количеству сока в миллилитрах.
Chain-of-Though промптинг - популярный способ заставить LLM делать что-то осмысленное, заставляя его "думать" пошагово и выводить промежуточные шаги размышления. Можно закидывать вместе с вопросом несколько примеров вопросов и шагов размышления, а можно просто нагло заявить "Let's think step by step." (что называется Zero-shot CoT prompting).

Если навалить большой языковой модели кучу всего в промпт (скажем, целую таблицу данных) и попросить сделать из этого какой-то вывод то, во-первых, она может начать галлюцинировать, а во-вторых, на действительно большую таблицу размера контекста не хватит. Авторы данной статьи пытаются декомпозировать resoning относительно таблицы, заставляя LLM работать в несколько приёмов. Сначала просят её сгенерировать промежуточные вопросы, потом написать для ответов на эти вопросы SQL, потом выполняют его и скармливают LLM для поиска окончательного ответа. Воспроизвести не удалось пока, примеры промптов в статье вроде как неполные.
#ml #llm #chain_of_though #prompt_engineering #llm_reasoning
Как языковые модели генерируют ответы? Подав на вход последовательность токенов промпта, мы получаем в ответ список вероятностей для следующего токена ответа. Далее мы можем использовать тупой жадный алгоритм - выбрать токен с самой большой вероятностью. Далее мы сабмитим в языковую модель всё то же, но с дописанным токеном ответа и всем остальным со сдвигом, и таким образом генерируем список возможных следующих токенов с вероятностями.
Но на практике не всегда используется тупой жадный алгоритм. Ведь надо выбрать наиболее вероятную последовательность токенов, которая может получиться плохой, если мы выбрали где-то на ранней стадии неудачно. Фактически нас интересует максимизация произведения вероятностей каждого следующего токена.
Есть такая система организации заметок, позволяющая аккумулировать полезные идеи и не давать им забываться, а заставлять их быть пищей для последующих размышлений.
Наверное, каждый homo sapiens sapiens замечал, что встречает в жизни много интересных кусочков информации, придумывает какие-то идеи, но не все из них получают развитие, на которое заслуживают. Что-то продолжаешь крутить в голове, а что-то забывается и вытесняется новыми поступлениями.
Автор системы оказался весьма плодовитым учёным и писателем, написав 70 книг и 400 статей. Видимо, просто кормил "экзокортекс" идеями, линковал их, а когда идеи собирались в достаточного объема комок, просто тянул за ниточки и вытягивал всё нужное, оставалась техническая работа по изложеннию всего.


#humor #libertarian

...we propose developing task-oriented prompts and automatically utilizing LLMs to automate the training pipeline. To implement this concept, we present the AutoML-GPT, which employs GPT as the bridge to diverse AI models and dynamically trains models with optimized hyperparameters. AutoML-GPT dynamically takes user requests from the model and data cards and composes the corresponding prompt paragraph. Ultimately, with this prompt paragraph, AutoML-GPT will automatically conduct the experiments from data processing to model architecture, hyperparameter tuning, and predicted training log. By leveraging {\ours}'s robust language capabilities and the available AI models, AutoML-GPT can tackle numerous intricate AI tasks across various tasks and datasets. This approach achieves remarkable results in computer vision, natural language processing, and other challenging areas. Extensive experiments and ablation studies demonstrate that our method can be general, effective, and beneficial for many AI tasks.
